





The New York-based company conducts sales through bi-weekly product drops, and faces challenges managing a significant influx of users arriving at their site within a narrow time frame. Their current setup encounters numerous bottlenecks, not only at the infrastructure layer, but also in the broader design of the application solution, requiring a comprehensive approach to address these performance and scalability issues.
The Client
This unconventional New York based company is known for their unique and often bizarre creations. They gained attention for limited-edition product drops that challenged traditional norms and expectations. The company aims to provoke conversations and critical thinking through their satirical approach.
Challenge
The client required assistance in designing a new infrastructure solution optimized for cost-effectiveness and capable of managing regular yet highly intensive spikes in traffic during product release events, often called drops, attended by hundreds of thousands of individuals. The primary challenge lays in scaling the infrastructure to accommodate thousands of users simultaneously within a mere minute or two. Additionally, support was required in shaping the application layer to be both performant and scalable, equipped to process large volumes of orders, users, and payment transactions.
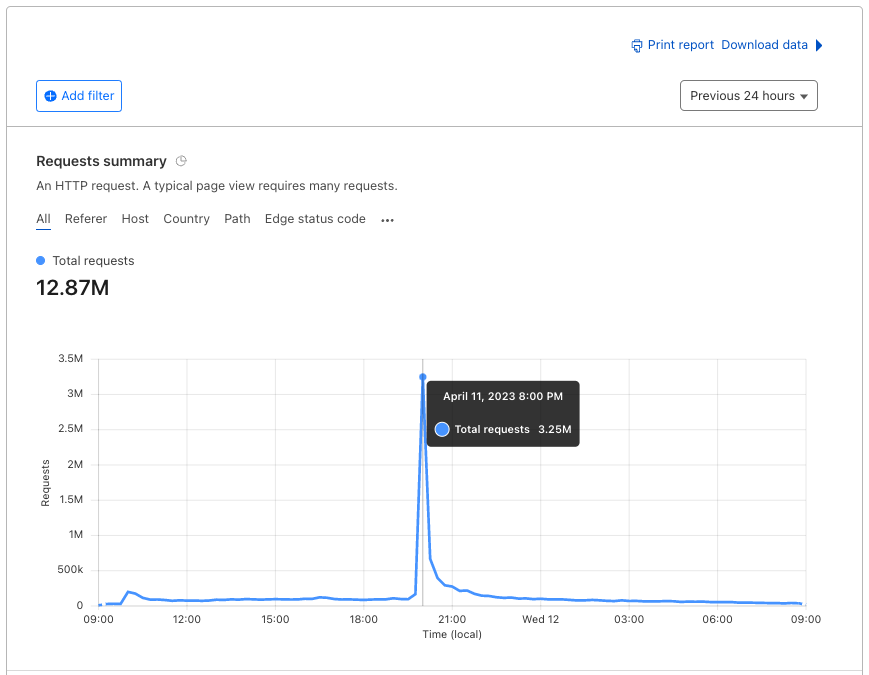
12 mil
requests per minute
Technology Stack
- Serverless framework, SST
- API Gateway, DynamoDB
- RDS
- Datadog
What We Did
Our design process for the client’s application architecture prioritized high scalability, utilizing an event-based architecture and serverless technologies and frameworks. After a successful proof of concept (PoC), we collaborated with the client to implement the final solution based on the Serverless framework. During the PoC phase, scaling of RDS and Lambda cold starts turned out to be the biggest bottleneck in our setup. Both of the key components needed to be scaled to a certain size before receiving the spike of user traffic at the beginning of each drop.
To address the need of handling large spikes in user traffic we implemented a pre-scale mechanism which automatically adjusted the sizes of instances used in the RDS cluster and utilised the provisioned concurrency feature of AWS Lambda, setting different weights on different Lambda groups based on actual demand on the solution.
The solution underwent a verification process, which included load testing to ensure robustness under high traffic. After the client’s verification, we established a long-term maintenance plan, involving regular upgrades and a commitment to continuous enhancements and improvements for optimum performance.




 WHAT’S NEXT?
WHAT’S NEXT?

